
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 포토샵
- 디자인
- CC
- haze #텐서플로 #tensorflow #ai
- 샤미르
- graph 3 coloring
- UX
- #암호학이론
- Shamir
- 블로그_이전_계획보다_지금_해야할게_더_많아서_유지예정
- 완전 비밀 분산
- zero knowledge proof
- 어도비
- Adobe
- 비밀 분산 기법
- Today
- Total
For Beginners
aod-net 사용하는 방법 정리해두기2 본문
분명 D드라이브 상에서 돌아가도록 경로 변경을 진행하였다.
저번에 C드라이브 상에서는 용량이 부족해서 메모리 에러가 났고, 다른 에러는 나지 않았는데,
이번에는 다른 에러가 났다.
Traceback (most recent call last):
File "create_train.py", line 105, in <module>
scipy.misc.imsave(saveimgdir+'/haze.jpg', haze_image)
File "C:\ProgramData\Anaconda3\lib\site-packages\numpy\lib\utils.py", line 101, in newfunc
return func(*args, **kwds)
File "C:\ProgramData\Anaconda3\lib\site-packages\scipy\misc\pilutil.py", line 219, in imsave
im.save(name)
File "C:\ProgramData\Anaconda3\lib\site-packages\PIL\Image.py", line 1966, in save
fp = builtins.open(filename, "w+b")
OSError: [Errno 22] Invalid argument: 'D:\\testing\\AODnet-by-pytorch\\datasets\\trainset/demo/haze.jpg'지금 보니까 일단 create_train.py의 105번째 줄에서 에러가 난 것 같다.
보니까 D:\\ 이런 식으로 argument가 들어갔다고 인식했고, slash에서 뭔가 에러가 난 것 같다.
그래서 argument을 내가 어떻게 입력을 했는지 보기로 했다.
(base) D:\testing\AODnet-by-pytorch\make_dataset>python create_train.py --nyu D:\testing\AODnet-by-pytorch --dataset D:\testing\AODnet-by-pytorch\datasets\trainset일단은 내가 입력한 부분에서는 slash나 \\를 반복하는 문제가 일어나지는 않았다.
create_train.py에 있는 코드를 읽어보기로 했다.
from __future__ import division
# torch condiguration
import argparse
import math
import os
import pdb
import pickle
import random
import shutil
import sys
import time
from math import log10
from random import uniform
import matplotlib.cm as cm
import matplotlib.patches as patches
import matplotlib.pyplot as plt
# import scipy.io as sio
import numpy as np
import PIL
import scipy
import scipy.io as sio
import scipy.ndimage.interpolation
from PIL import Image
import h5py
sys.path.append("./mingqingscript")
plt.ion()
def array2PIL(arr, size):
mode = 'RGBA'
arr = arr.reshape(arr.shape[0] * arr.shape[1], arr.shape[2])
if len(arr[0]) == 3:
arr = np.c_[arr, 255 * np.ones((len(arr), 1), np.uint8)]
return Image.frombuffer(mode, size, arr.tostring(), 'raw', mode, 0, 1)
parser = argparse.ArgumentParser()
parser.add_argument('--nyu', type=str, required=True, help='path to nyu_depth_v2_labeled.mat')
parser.add_argument('--dataset', type=str, require=True, help='path to synthesized hazy images dataset store')
args = parser.parse_args()
print(args)
index = 1
nyu_depth = h5py.File(args.nyu + '/nyu_depth_v2_labeled.mat', 'r')
directory = args.dataset + '/train'
saveimgdir = args.dataset + '/demo'
if not os.path.exists(directory):
os.makedirs(directory)
if not os.path.exists(saveimgdir):
os.makedirs(saveimgdir)
image = nyu_depth['images']
depth = nyu_depth['depths']
img_size = 224
# per=np.random.permutation(1400)
# np.save('rand_per.py',per)
# pdb.set_trace()
total_num = 0
plt.ion()
for index in range(1445):
index = index
gt_image = (image[index, :, :, :]).astype(float)
gt_image = np.swapaxes(gt_image, 0, 2)
gt_image = scipy.misc.imresize(gt_image, [480, 640]).astype(float)
gt_image = gt_image / 255
gt_depth = depth[index, :, :]
maxhazy = gt_depth.max()
minhazy = gt_depth.min()
gt_depth = (gt_depth) / (maxhazy)
gt_depth = np.swapaxes(gt_depth, 0, 1)
for j in range(7):
for k in range(3):
#beta
bias = 0.05
temp_beta = 0.4 + 0.2*j
beta = uniform(temp_beta-bias, temp_beta+bias)
tx1 = np.exp(-beta * gt_depth)
#A
abias = 0.1
temp_a = 0.5 + 0.2*k
a = uniform(temp_a-abias, temp_a+abias)
A = [a,a,a]
m = gt_image.shape[0]
n = gt_image.shape[1]
rep_atmosphere = np.tile(np.reshape(A, [1, 1, 3]), [m, n, 1])
tx1 = np.reshape(tx1, [m, n, 1])
max_transmission = np.tile(tx1, [1, 1, 3])
haze_image = gt_image * max_transmission + rep_atmosphere * (1 - max_transmission)
total_num = total_num + 1
scipy.misc.imsave(saveimgdir+'/haze.jpg', haze_image)
scipy.misc.imsave(saveimgdir+'/gt.jpg', gt_image)
h5f=h5py.File(directory+'/'+str(total_num)+'.h5','w')
h5f.create_dataset('haze',data=haze_image)
h5f.create_dataset('gt',data=gt_image)보니까 일단은 여기서 디렉터리를 잘못 입력하고 있는 것 같았다.
일단 절대 경로로 표시함으로 인해서 \\로 표시되는 상황을 막아주었다.
python create_train.py --nyu ../ --dataset ../datasets/trainset일단은 이렇게 입력해주었다.
아까보다 경로는 간단해졌으나, 직관적으로 입력하는 것이 아니라서 오류가 날 각오를 하면서 보고 있었다.
흠 아까는 1200 번대 training 파일을 만들면서 에러가 났는데, 이번에는 2000번이 될 때까지 에러가 나지 않았다.
Traceback (most recent call last):
File "create_train.py", line 106, in <module>
scipy.misc.imsave(saveimgdir+'/gt.jpg', gt_image)
File "C:\ProgramData\Anaconda3\lib\site-packages\numpy\lib\utils.py", line 101, in newfunc
return func(*args, **kwds)
File "C:\ProgramData\Anaconda3\lib\site-packages\scipy\misc\pilutil.py", line 219, in imsave
im.save(name)
File "C:\ProgramData\Anaconda3\lib\site-packages\PIL\Image.py", line 1966, in save
fp = builtins.open(filename, "w+b")
OSError: [Errno 22] Invalid argument: '../datasets/trainset/demo/gt.jpg'앗 근데 2400번대 training파일을 만들면서 에러가 났다.
이번에는 경로도 잘 입력해서 문제가 없을 거라고 생각했는데, 왜 문제가 생겼는지 모르겠다...
심지어 경로 상에 demo/gt.jpg가 존재하는 것으로 눈으로 보고 있었는데...
일단 코드를 한 번 더 돌려보기로 했다.
기존에 학습된 아이들은 자동으로 덮어 씌워지므로, 걱정할 필요가 없다.
이번에는 500번대에서 에러가 났다.
과연 뭐가 문제일지.... 모르겠다. 아직까지는......
일단은 경로 자체가 뭔가 string을 취급하는 slash부분에 문제가 있는 거라고 여기고 slash를 다르게 바꾸어보았다.
total_num = total_num + 1
scipy.misc.imsave(saveimgdir+'\haze.jpg', haze_image)
scipy.misc.imsave(saveimgdir+'\gt.jpg', gt_image)
h5f = h5py.File(os.path.join(directory,str(total_num)+".h5"),'w')
h5f.create_dataset('haze',data=haze_image)
h5f.create_dataset('gt',data=gt_image)끝의 6 문장을 다음과 같이 바꾸었다.
os.path.join()이라는 함수는 https://wikidocs.net/3716 여기를 참고했다.
근데 이렇게 하니까 일단 돌려봤을 때 12000번대 넘게 training set을 생성했다.
확실히 경로 문제가 맞은듯했다.
왜 사진을 processing 하던 도중에 에러가 나는지는 잘 모르겠지만, 경로문제라는 것을 알았으니, 앞으로도 경로를 잘 바꾸어주어야겠다는 생각이 들었다.
앞으로 이런식으로 계속 경로 바꿔줄 생각하니까 짜릿하다.
내가 처음에 training set을 만들고 random select를 통해 validation을 하고, train과 test를 진행하는 코드는 다음과 같이 진행된다.
D:
cd D:\testing\AODnet-by-pytorch\make_dataset
python create_train.py --nyu ../ --dataset ../datasets/trainset
python random_select.py --trainroot ../datasets/trainset/train --valroot ../datasets/valset
cd ..
python train.py --dataroot ./datasets/trainset/train --valDataroot ./datasets/valset --cuda
python test.py --input_image ./test/canyon1.jpg --model /model_pretrained/AOD_net_epoch_relu_10.pth --output_filename ./result/canyon1_dehaze.jpg --cuda일단 training set을 만드는데에는 성공했다.
(base) D:\testing\AODnet-by-pytorch\make_dataset>python create_train.py --nyu ../ --dataset ../datasets/trainset
Namespace(dataset='../datasets/trainset', nyu='../')
(base) D:\testing\AODnet-by-pytorch\make_dataset>이런식으로 나오게 되면 성공이다.
set의 개수는
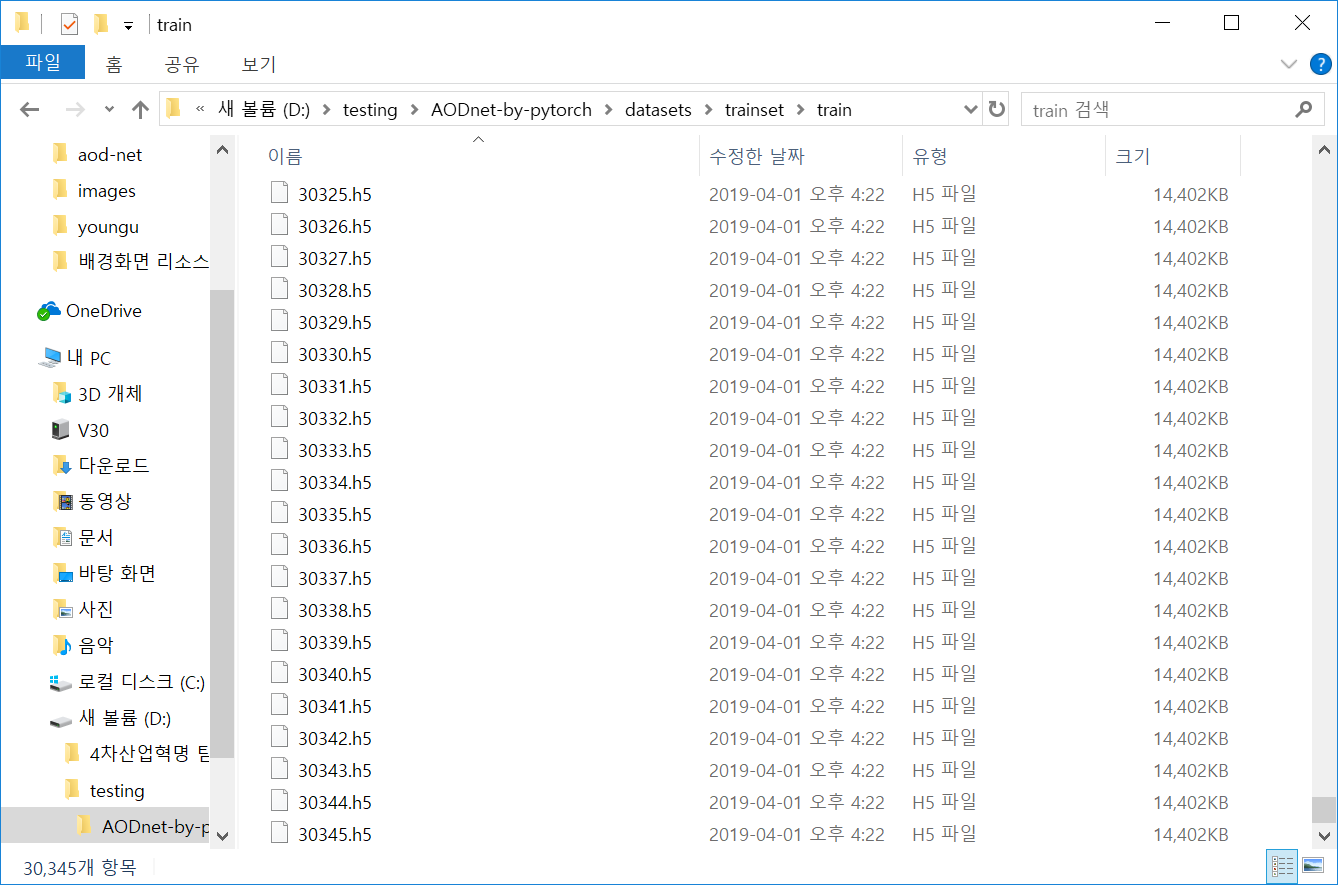
30345개가 되는 것 같다.
그래서 이제
python random_select.py --trainroot ../datasets/trainset --valroot ../datasets/valset랜덤하게 validation 할 set들을 select했다.
(base) D:\testing\AODnet-by-pytorch\make_dataset>python random_select.py --trainroot ../datasets/trainset --valroot ../datasets/valset
Namespace(trainroot='../datasets/trainset', valroot='../datasets/valset')
(base) D:\testing\AODnet-by-pytorch\make_dataset>그렇게 되면 select하는 시간은 굉장히 짧다.
근데 이상한 것이 valset에 있어야 할 애들이 아예 디렉토리에 없는 것이었다.
특별한 에러메세지가 없는 것으로 보아 내가 잠깐 코드를 고친 부분을 빼먹고 주석처리한 내용을 빼지 않았던 것 같다.
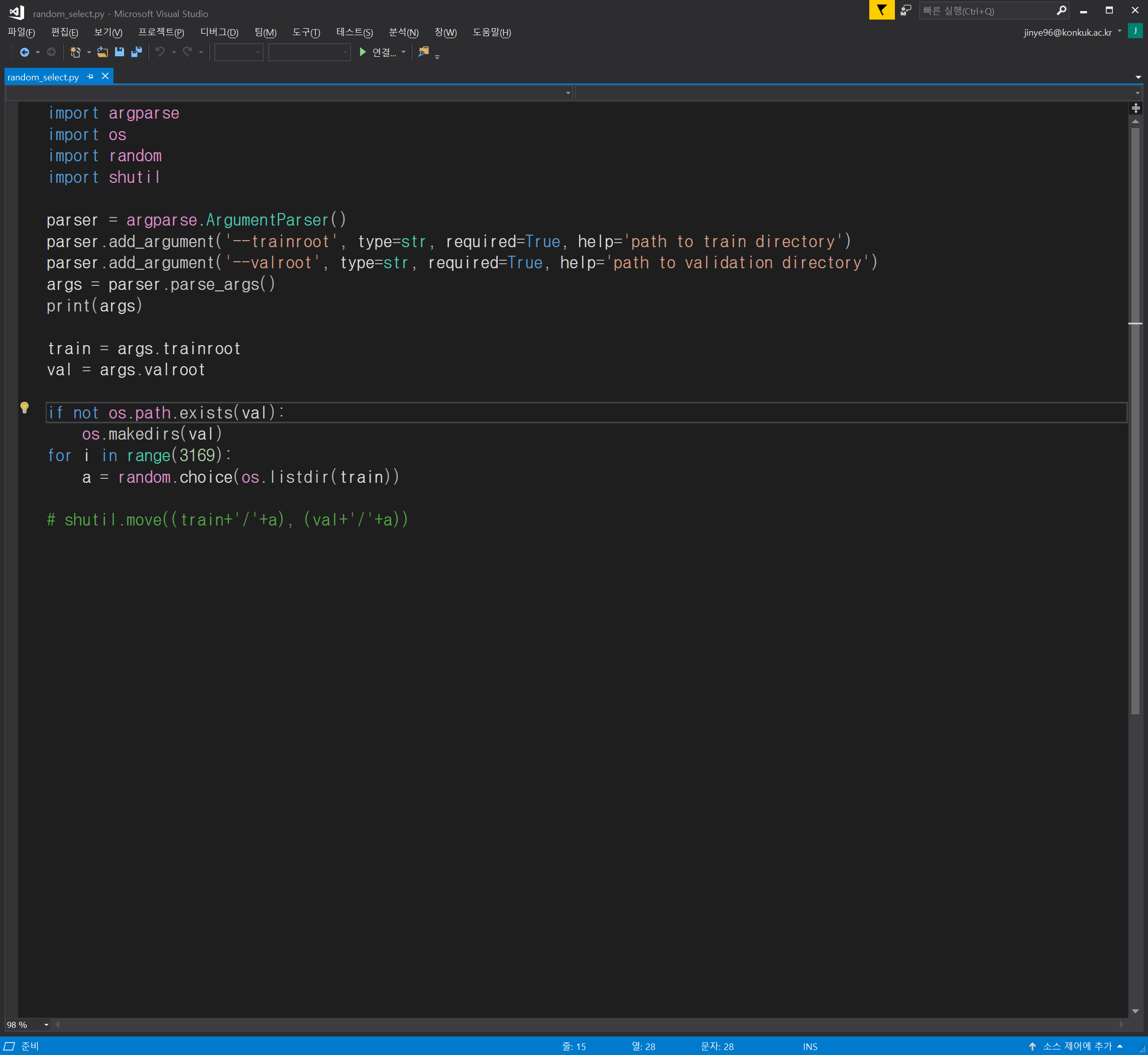
아니나 다를까
파일을 이동시키는 부분을 주석으로 빼먹었다.
import argparse
import os
import random
import shutil
parser = argparse.ArgumentParser()
parser.add_argument('--trainroot', type=str, required=True, help='path to train directory')
parser.add_argument('--valroot', type=str, required=True, help='path to validation directory')
args = parser.parse_args()
print(args)
train = args.trainroot
val = args.valroot
if not os.path.exists(val):
os.makedirs(val)
for i in range(3169):
a = random.choice(os.listdir(train))
shutil.move((train+'/'+a), (val+'/'+a))
주석으로 된 부분을 해제시키고, 다시 실행해보았다.
그러니까 train에 있는 값이 일부가 선택되는 것이 아니라, 모든 값들이 다 이동하는 것으로 보아 이것도 무언가가 잘못되었다는 것을 깨달았다.
파이썬을 공부하면서 깨달았다.
왜 모든 파일이 이동되었냐면, move구문이 for안에 안들어가 있어서인 것같다.
그래서 노가다를 이용해서... 하유 경로가 잘못되어서 이동 잘못하니까 30000만개의 이미지를 옮겨야 하고, cpu가 좋은 사람들이야 괜찮겠지만, 나로서는 시간적 리스크가 너무 크다.
(base) D:\testing\AODnet-by-pytorch\make_dataset>python random_select.py --trainroot ../datasets/trainset --valroot ../datasets/valset
Namespace(trainroot='../datasets/trainset', valroot='../datasets/valset')
Traceback (most recent call last):
File "random_select.py", line 18, in <module>
a = random.choice(os.listdir(train))
File "C:\ProgramData\Anaconda3\lib\random.py", line 260, in choice
raise IndexError('Cannot choose from an empty sequence') from None
IndexError: Cannot choose from an empty sequence이런 에러가 나서 찾아보니까 train에 있는 디렉토리로 경로를 설정해놔야되는 것 같았다.
그래서 이렇게 명령을 바꾸어주었다.
(base) D:\testing\AODnet-by-pytorch\make_dataset>python random_select.py --trainroot ../datasets/trainset/train --valroot ../datasets/valset
Namespace(trainroot='../datasets/trainset/train', valroot='../datasets/valset')헤유 이러니까 잘 돌아가는 것 같다.
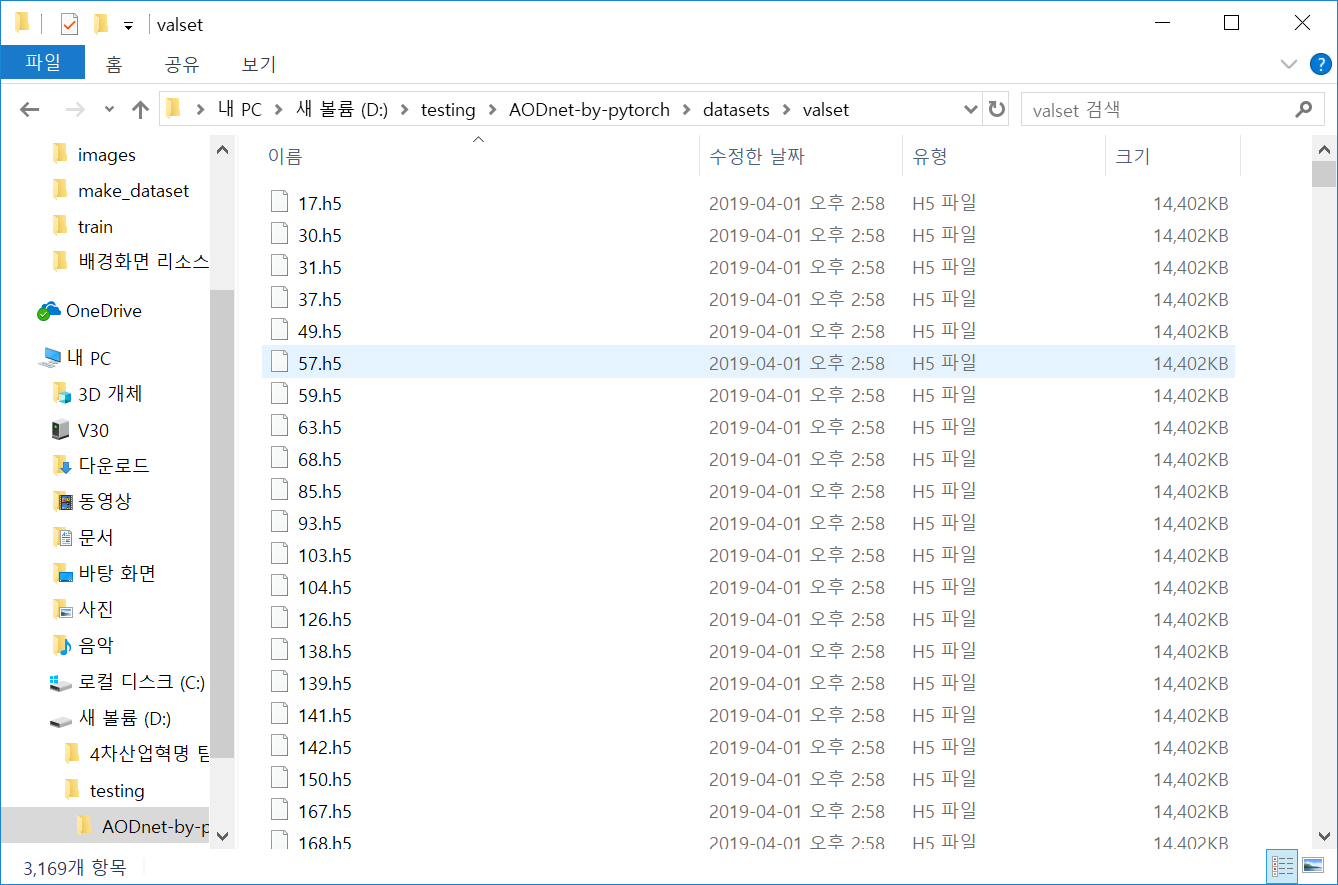
이런 식으로 랜덤으로 training값이 뽑혀서 나온다.
이 training set은 training을 하면서 모델링을 하는데 기준이 되는 중간테스트용 자료라고 볼 수 있다.
일단은 원래의 모습으로 돌아가야 한다.
cd ..
python train.py --dataroot ./datasets/trainset/train --valDataroot ./datasets/valset --cuda
근데 갑자기 이걸 돌리니까 이런 에러가 나는 것이다.
(base) D:\testing\AODnet-by-pytorch>python train.py --dataroot ./datasets/trainset/train --valDataroot ./datasets/valset --cuda
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 2880
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 5052
===> Building model
Traceback (most recent call last):
File "<string>", line 1, in <module>
Traceback (most recent call last):
File "train.py", line 153, in <module>
train(epoch)
File "train.py", line 108, in train
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 105, in spawn_main
for iteration, batch in enumerate(trainDataloader, 0):
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 819, in __iter__
exitcode = _main(fd)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 114, in _main
prepare(preparation_data)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 225, in prepare
_fixup_main_from_path(data['init_main_from_path'])return _DataLoaderIter(self)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 277, in _fixup_main_from_path
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in __init__
run_name="__mp_main__")w.start()
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 263, in run_path
File "C:\ProgramData\Anaconda3\lib\multiprocessing\process.py", line 105, in start
pkg_name=pkg_name, script_name=fname)
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 96, in _run_module_code
self._popen = self._Popen(self)
mod_name, mod_spec, pkg_name, script_name) File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 223, in _Popen
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "D:\testing\AODnet-by-pytorch\train.py", line 153, in <module>
return _default_context.get_context().Process._Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 322, in _Popen
train(epoch)
File "D:\testing\AODnet-by-pytorch\train.py", line 108, in train
return Popen(process_obj)for iteration, batch in enumerate(trainDataloader, 0):
File "C:\ProgramData\Anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 819, in __iter__
reduction.dump(process_obj, to_child)
return _DataLoaderIter(self) File "C:\ProgramData\Anaconda3\lib\multiprocessing\reduction.py", line 60, in dump
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in __init__
ForkingPickler(file, protocol).dump(obj)
w.start()BrokenPipeError
: File "C:\ProgramData\Anaconda3\lib\multiprocessing\process.py", line 105, in start
[Errno 32] Broken pipe
self._popen = self._Popen(self)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 33, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 143, in get_preparation_data
_check_not_importing_main()
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 136, in _check_not_importing_main
is not going to be frozen to produce an executable.''')
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
(base) D:\testing\AODnet-by-pytorch>메인 모듈에 freeze_support()를 넣어주어야 하는 것 같다.
이 부분은 에러가 맞는 것 같으니 한번 다른 troubleshotting 사이트를 찾아보아야 겠다.
https://github.com/pytorch/pytorch/issues/5858
RuntimeError: freeze_support() · Issue #5858 · pytorch/pytorch
OS: windows 10 PyTorch version: 0.3.1.post2 How you installed PyTorch (conda, pip, source): conda install -c peterjc123 pytorch-cpu Python version: 3.5.4 Error Message: C:\Install\Anaconda3\envs\am...
github.com
찾아보았는데, 아무래도 본 코드에 뭔가 필수적인 코드가 들어갔어야 했는데 안들어가서 pytorch상에서 에러가 난 듯했다. 그래서 일단 python 코드에서 에러가 났던 train.py라는 코드에 넣으라는 부분을 넣어보기로 했다.
import argparse
import os
import random
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.parallel
import torch.optim as optim
import torchvision.utils as vutils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import AODnet
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=False, default='pix2pix', help='')
parser.add_argument('--dataroot', required=True, help='path to trn dataset')
parser.add_argument('--valDataroot', required=True, help='path to val dataset')
parser.add_argument('--valBatchSize', type=int, default=32, help='input batch size')
parser.add_argument('--cuda', action='store_true', help='use cuda?')
parser.add_argument('--lr', type=float, default=1e-4, help='Learning Rate. Default=1e-4')
parser.add_argument('--threads', type=int, default=4, help='number of threads for data loader to use, if Your OS is window, please set to 0')
parser.add_argument('--exp', default='pretrain', help='folder to model checkpoints')
parser.add_argument('--printEvery', type=int, default=50, help='number of batches to print average loss ')
parser.add_argument('--batchSize', type=int, default=32, help='training batch size')
parser.add_argument('--epochSize', type=int, default=840, help='number of batches as one epoch (for validating once)')
parser.add_argument('--nEpochs', type=int, default=10, help='number of epochs for training')
args = parser.parse_args()
print(args)
args.manualSeed = random.randint(1, 10000)
random.seed(args.manualSeed)
torch.manual_seed(args.manualSeed)
torch.cuda.manual_seed_all(args.manualSeed)
print("Random Seed: ", args.manualSeed)
#===== Dataset =====
def getLoader(datasetName, dataroot, batchSize, workers,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), split='train', shuffle=True, seed=None):
if datasetName == 'pix2pix':
from datasets.pix2pix import pix2pix as commonDataset
import transforms.pix2pix as transforms
if split == 'train':
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
else:
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batchSize,
shuffle=shuffle,
num_workers=int(workers))
return dataloader
trainDataloader = getLoader(args.dataset,
args.dataroot,
args.batchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='train',
shuffle=True,
seed=args.manualSeed)
valDataloader = getLoader(args.dataset,
args.valDataroot,
args.valBatchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='val',
shuffle=False,
seed=args.manualSeed)
#===== DehazeNet =====
print('===> Building model')
net = AODnet()
if args.cuda:
net = net.cuda()
#===== Loss function & optimizer =====
criterion = torch.nn.MSELoss()
if args.cuda:
criterion = criterion.cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=args.lr, weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=53760, gamma=0.5)
#===== Training and validation procedures =====
def train(epoch):
net.train()
epoch_loss = 0
for iteration, batch in enumerate(trainDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varIn.float(), varTar.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
# print(iteration)
optimizer.zero_grad()
loss = criterion(net(varIn), varTar)
# print(loss)
epoch_loss += loss.data[0]
loss.backward()
optimizer.step()
if iteration%args.printEvery == 0:
print("===> Epoch[{}]({}/{}): Avg. Loss: {:.4f}".format(epoch, iteration+1, len(trainDataloader), epoch_loss/args.printEvery))
epoch_loss = 0
def validate():
net.eval()
avg_mse = 0
for _, batch in enumerate(valDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varTar.float(), varIn.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
prediction = net(varIn)
mse = criterion(prediction, varTar)
avg_mse += mse.data[0]
print("===>Avg. Loss: {:.4f}".format(avg_mse/len(valDataloader)))
def checkpoint(epoch):
model_out_path = "./model_pretrained/AOD_net_epoch_relu_{}.pth".format(epoch)
torch.save(net, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
#===== Main procedure =====
for epoch in range(1, args.nEpochs + 1):
train(epoch)
validate()
checkpoint(epoch)
def run():
torch.multiprocessing.freeze_support()
print('loop')
if __name__ == '__main__':
run()이런 식으로, 맨 뒤에 definition 을 추가해주었다.
(base) D:\testing\AODnet-by-pytorch>python train.py --dataroot ./datasets/trainset/train --valDataroot ./datasets/valset --cuda
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 9284
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 8789
===> Building model
Traceback (most recent call last):
File "<string>", line 1, in <module>
Traceback (most recent call last):
File "train.py", line 153, in <module>
train(epoch)
File "train.py", line 108, in train
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 105, in spawn_main
for iteration, batch in enumerate(trainDataloader, 0):
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 819, in __iter__
exitcode = _main(fd)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 114, in _main
return _DataLoaderIter(self)prepare(preparation_data)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in __init__
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 225, in prepare
w.start()
_fixup_main_from_path(data['init_main_from_path']) File "C:\ProgramData\Anaconda3\lib\multiprocessing\process.py", line 105, in start
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 277, in _fixup_main_from_path
self._popen = self._Popen(self)
run_name="__mp_main__") File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 223, in _Popen
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 263, in run_path
return _default_context.get_context().Process._Popen(process_obj)pkg_name=pkg_name, script_name=fname)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 322, in _Popen
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)return Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 85, in _run_code
File "C:\ProgramData\Anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 65, in __init__
exec(code, run_globals)
File "D:\testing\AODnet-by-pytorch\train.py", line 153, in <module>
reduction.dump(process_obj, to_child)train(epoch)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\reduction.py", line 60, in dump
File "D:\testing\AODnet-by-pytorch\train.py", line 108, in train
ForkingPickler(file, protocol).dump(obj)for iteration, batch in enumerate(trainDataloader, 0):
BrokenPipeError File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 819, in __iter__
: [Errno 32] Broken pipe
return _DataLoaderIter(self)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in __init__
w.start()
File "C:\ProgramData\Anaconda3\lib\multiprocessing\process.py", line 105, in start
self._popen = self._Popen(self)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 33, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 143, in get_preparation_data
_check_not_importing_main()
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 136, in _check_not_importing_main
is not going to be frozen to produce an executable.''')
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.그래도 같은 문제가 생겼다.
그래서 뭐가 문제일까...하고 에러코드를 뜯어봤다.
근데 내가 사용하고 있는 오픈소스의 경우, 함수가 다 정의가 되어있었고,
메인 스레드 상에서 사용하는 함수가 세가지나 되어서, 메인 함수가 무엇인지 파악하기가 어려웠다.
ㅠㅠ 아무래도 오늘 중으로는 에러를 찾기가 어려울 것 같다.
import argparse
import os
import random
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.parallel
import torch.optim as optim
import torchvision.utils as vutils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import AODnet
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=False, default='pix2pix', help='')
parser.add_argument('--dataroot', required=True, help='path to trn dataset')
parser.add_argument('--valDataroot', required=True, help='path to val dataset')
parser.add_argument('--valBatchSize', type=int, default=32, help='input batch size')
parser.add_argument('--cuda', action='store_true', help='use cuda?')
parser.add_argument('--lr', type=float, default=1e-4, help='Learning Rate. Default=1e-4')
parser.add_argument('--threads', type=int, default=4, help='number of threads for data loader to use, if Your OS is window, please set to 0')
parser.add_argument('--exp', default='pretrain', help='folder to model checkpoints')
parser.add_argument('--printEvery', type=int, default=50, help='number of batches to print average loss ')
parser.add_argument('--batchSize', type=int, default=32, help='training batch size')
parser.add_argument('--epochSize', type=int, default=840, help='number of batches as one epoch (for validating once)')
parser.add_argument('--nEpochs', type=int, default=10, help='number of epochs for training')
args = parser.parse_args()
print(args)
args.manualSeed = random.randint(1, 10000)
random.seed(args.manualSeed)
torch.manual_seed(args.manualSeed)
torch.cuda.manual_seed_all(args.manualSeed)
print("Random Seed: ", args.manualSeed)
#===== Dataset =====
def getLoader(datasetName, dataroot, batchSize, workers,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), split='train', shuffle=True, seed=None):
if datasetName == 'pix2pix':
from datasets.pix2pix import pix2pix as commonDataset
import transforms.pix2pix as transforms
if split == 'train':
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
else:
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batchSize,
shuffle=shuffle,
num_workers=int(workers))
return dataloader
trainDataloader = getLoader(args.dataset,
args.dataroot,
args.batchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='train',
shuffle=True,
seed=args.manualSeed)
valDataloader = getLoader(args.dataset,
args.valDataroot,
args.valBatchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='val',
shuffle=False,
seed=args.manualSeed)
#===== DehazeNet =====
print('===> Building model')
net = AODnet()
if args.cuda:
net = net.cuda()
#===== Loss function & optimizer =====
criterion = torch.nn.MSELoss()
if args.cuda:
criterion = criterion.cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=args.lr, weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=53760, gamma=0.5)
#===== Training and validation procedures =====
def train(epoch):
net.train()
epoch_loss = 0
for iteration, batch in enumerate(trainDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varIn.float(), varTar.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
# print(iteration)
optimizer.zero_grad()
loss = criterion(net(varIn), varTar)
# print(loss)
epoch_loss += loss.data[0]
loss.backward()
optimizer.step()
if iteration%args.printEvery == 0:
print("===> Epoch[{}]({}/{}): Avg. Loss: {:.4f}".format(epoch, iteration+1, len(trainDataloader), epoch_loss/args.printEvery))
epoch_loss = 0
def validate():
net.eval()
avg_mse = 0
for _, batch in enumerate(valDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varTar.float(), varIn.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
prediction = net(varIn)
mse = criterion(prediction, varTar)
avg_mse += mse.data[0]
print("===>Avg. Loss: {:.4f}".format(avg_mse/len(valDataloader)))
def checkpoint(epoch):
model_out_path = "./model_pretrained/AOD_net_epoch_relu_{}.pth".format(epoch)
torch.save(net, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
#===== Main procedure =====
for epoch in range(1, args.nEpochs + 1):
train(epoch)
validate()
checkpoint(epoch)이 에러를 어떻게 해결했냐면
내가 지금 소속되어 있는 멋쟁이 사자처럼 멘토님께 여쭤보았다!
멘토님 바쁘실텐데도 파이참이랑 깃헙 클론까지 하시고 내 질문에 완벽한 답을 주셨다ㅠㅠㅠ
import argparse
import os
import random
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.parallel
import torch.optim as optim
import torchvision.utils as vutils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import AODnet
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=False, default='pix2pix', help='')
parser.add_argument('--dataroot', required=True, help='path to trn dataset')
parser.add_argument('--valDataroot', required=True, help='path to val dataset')
parser.add_argument('--valBatchSize', type=int, default=32, help='input batch size')
parser.add_argument('--cuda', action='store_true', help='use cuda?')
parser.add_argument('--lr', type=float, default=1e-4, help='Learning Rate. Default=1e-4')
parser.add_argument('--threads', type=int, default=4, help='number of threads for data loader to use, if Your OS is window, please set to 0')
parser.add_argument('--exp', default='pretrain', help='folder to model checkpoints')
parser.add_argument('--printEvery', type=int, default=50, help='number of batches to print average loss ')
parser.add_argument('--batchSize', type=int, default=32, help='training batch size')
parser.add_argument('--epochSize', type=int, default=840, help='number of batches as one epoch (for validating once)')
parser.add_argument('--nEpochs', type=int, default=10, help='number of epochs for training')
args = parser.parse_args()
print(args)
args.manualSeed = random.randint(1, 10000)
random.seed(args.manualSeed)
torch.manual_seed(args.manualSeed)
torch.cuda.manual_seed_all(args.manualSeed)
print("Random Seed: ", args.manualSeed)
#===== Dataset =====
def getLoader(datasetName, dataroot, batchSize, workers,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), split='train', shuffle=True, seed=None):
if datasetName == 'pix2pix':
from datasets.pix2pix import pix2pix as commonDataset
import transforms.pix2pix as transforms
if split == 'train':
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
else:
dataset = commonDataset(root=dataroot,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std),
]),
seed=seed)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batchSize,
shuffle=shuffle,
num_workers=int(workers))
return dataloader
trainDataloader = getLoader(args.dataset,
args.dataroot,
args.batchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='train',
shuffle=True,
seed=args.manualSeed)
valDataloader = getLoader(args.dataset,
args.valDataroot,
args.valBatchSize,
args.threads,
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
split='val',
shuffle=False,
seed=args.manualSeed)
#===== DehazeNet =====
print('===> Building model')
net = AODnet()
if args.cuda:
net = net.cuda()
#===== Loss function & optimizer =====
criterion = torch.nn.MSELoss()
if args.cuda:
criterion = criterion.cuda()
optimizer = torch.optim.Adam(net.parameters(), lr=args.lr, weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=53760, gamma=0.5)
#===== Training and validation procedures =====
def train(epoch):
torch.multiprocessing.freeze_support()
net.train()
epoch_loss = 0
for iteration, batch in enumerate(trainDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varIn.float(), varTar.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
# print(iteration)
optimizer.zero_grad()
loss = criterion(net(varIn), varTar)
# print(loss)
epoch_loss += loss.data[0]
loss.backward()
optimizer.step()
if iteration%args.printEvery == 0:
print("===> Epoch[{}]({}/{}): Avg. Loss: {:.4f}".format(epoch, iteration+1, len(trainDataloader), epoch_loss/args.printEvery))
epoch_loss = 0
def validate():
net.eval()
avg_mse = 0
for _, batch in enumerate(valDataloader, 0):
varIn, varTar = Variable(batch[0]), Variable(batch[1])
varIn, varTar = varTar.float(), varIn.float()
if args.cuda:
varIn = varIn.cuda()
if args.cuda:
varTar = varTar.cuda()
prediction = net(varIn)
mse = criterion(prediction, varTar)
avg_mse += mse.data[0]
print("===>Avg. Loss: {:.4f}".format(avg_mse/len(valDataloader)))
def checkpoint(epoch):
model_out_path = "./model_pretrained/AOD_net_epoch_relu_{}.pth".format(epoch)
torch.save(net, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
#===== Main procedure =====
def main():
for epoch in range(1, args.nEpochs + 1):
train(epoch)
validate()
checkpoint(epoch)
if __name__ == '__main__':
main()위 내용은 멘토님의 힘을 빌어서 코드를 변경한 내용이다.
계속 freeze_어쩌구가 떠서 굉장히 힘겨웠는데.... 드디어 해결!
(base) D:\testing\AODnet-by-pytorch>python train.py --dataroot ./datasets/trainset/train --valDataroot ./datasets/valset --cuda
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 2004
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 5395
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 7659
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 2596
===> Building model
Namespace(batchSize=32, cuda=True, dataroot='./datasets/trainset/train', dataset='pix2pix', epochSize=840, exp='pretrain', lr=0.0001, nEpochs=10, printEvery=50, threads=4, valBatchSize=32, valDataroot='./datasets/valset')
Random Seed: 5791
===> Building model
Traceback (most recent call last):
File "train.py", line 156, in <module>
train(epoch)
File "train.py", line 120, in train
loss = criterion(net(varIn), varTar)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "D:\testing\AODnet-by-pytorch\model.py", line 18, in forward
x1 = F.relu(self.conv1(x))
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\nn\modules\conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 112.50 MiB (GPU 0; 2.00 GiB total capacity; 225.01 MiB already allocated; 26.58 MiB free; 1013.50 KiB cached)이런 에러가 뜨긴 했는데, 이 에러는 내 컴에 cpu만 장착되어 있고, GPU가 없어서 그런 문제라고 생각되어진다.
내일은 GPU가 있는 환경에서 진행해봐야지~
'2021 이전 자료들 > AI' 카테고리의 다른 글
| [Pytorch] Lecture 01 , Overview (0) | 2019.05.15 |
|---|---|
| [Pytorch 정리] 시작합니다. (0) | 2019.05.15 |
| aod-net 사용하는 방법 정리해두기 (2) | 2019.03.27 |
| [인공지능]-1 (1) | 2018.12.26 |
| [인공지능] 패턴인식2 (2) | 2017.12.04 |